Azure Data Factory orchestrates enterprise data movement and transformation across APIs, Azure SQL, Cosmos DB, files, storage, Databricks, Power BI, ML pipelines, and modern cloud data platforms.
Data Factory becomes the managed orchestration layer that connects source systems, linked services, datasets, transformations, Databricks, and reporting outputs into one repeatable enterprise data pipeline pattern.
The screenshots below use direct Microsoft Learn image paths for actual Azure Data Factory and Synapse pipeline screens. They show pipelines, data flow activities, linked services, datasets, transformation logic, debug output, and monitoring.
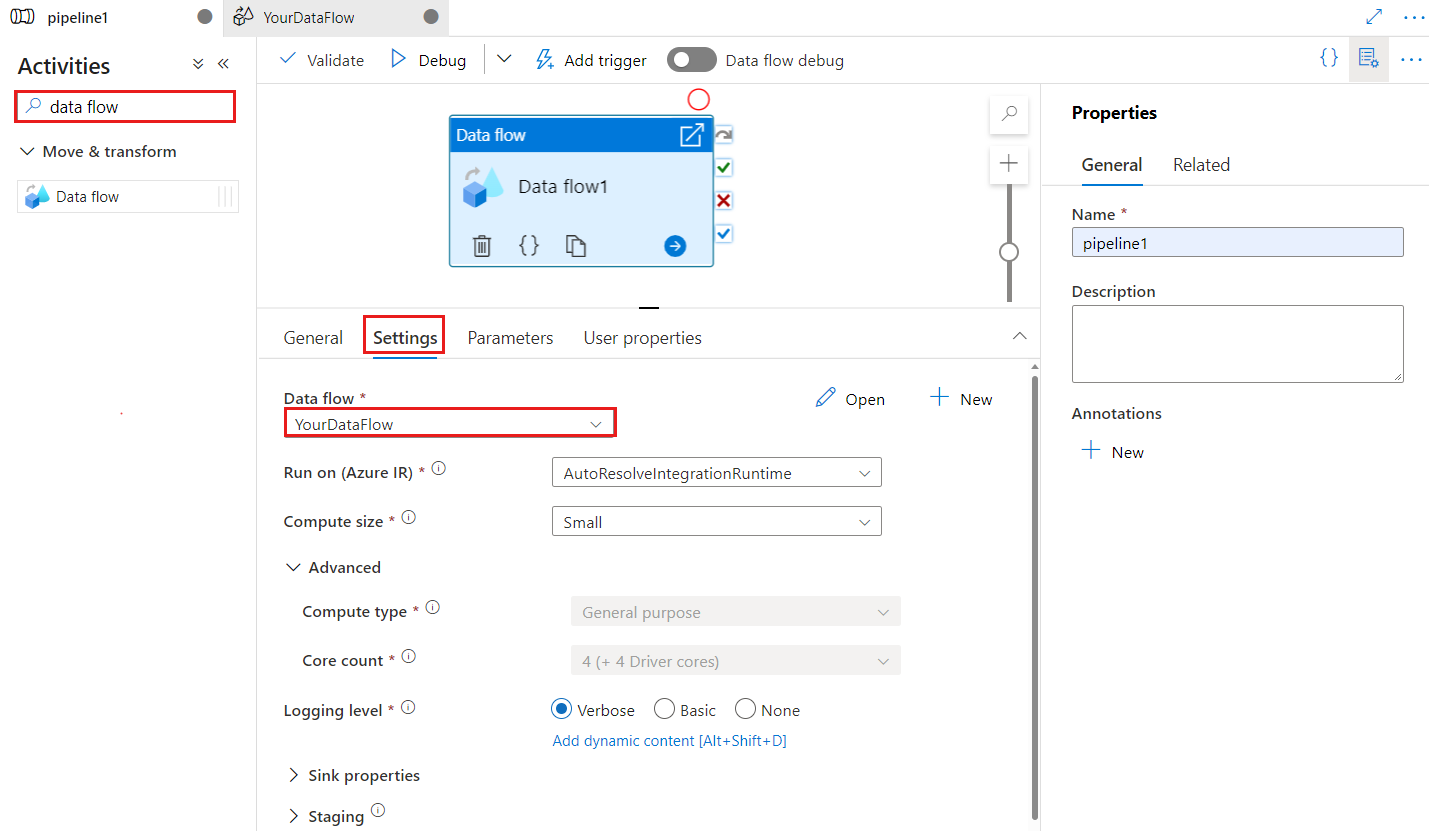
ADF pipelines visually orchestrate activities such as Data Flow, Copy, notebook execution, lookups, and conditional logic.
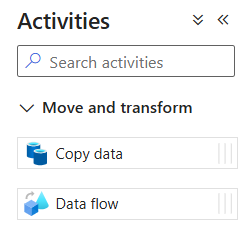
The activity pane shows the core building blocks used to move and transform data across enterprise systems.
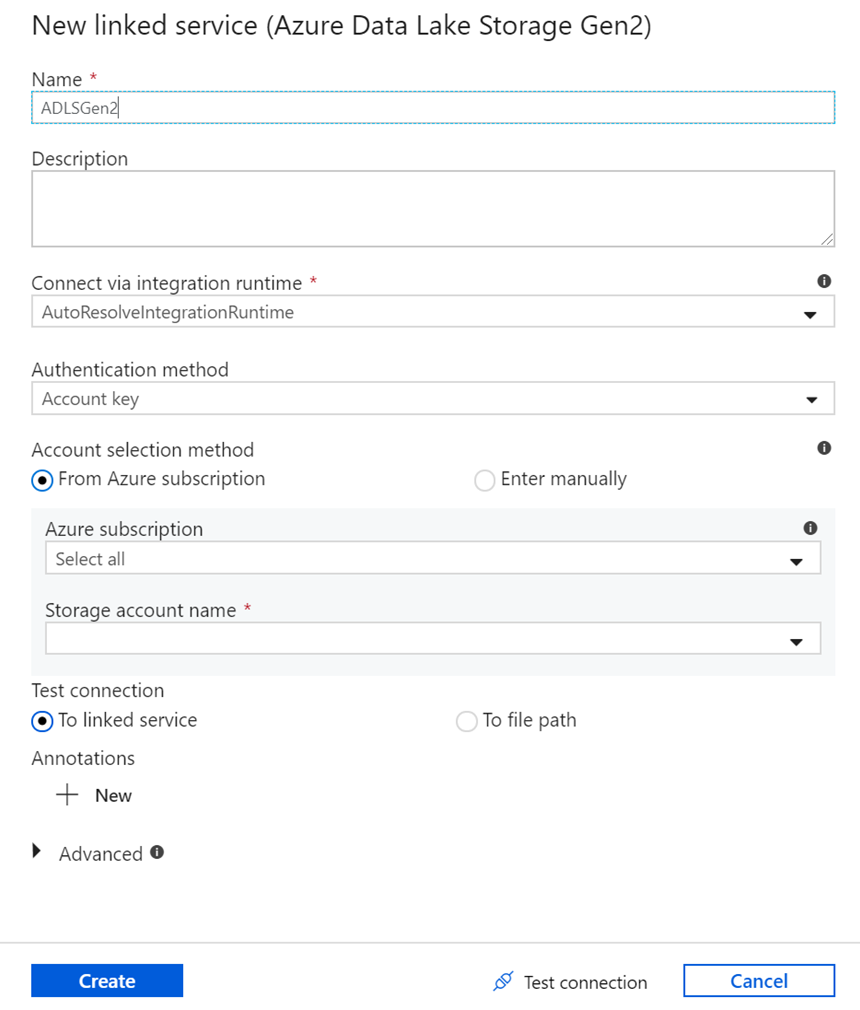
Linked services securely connect ADF to source and destination systems such as storage, SQL, APIs, and compute services.
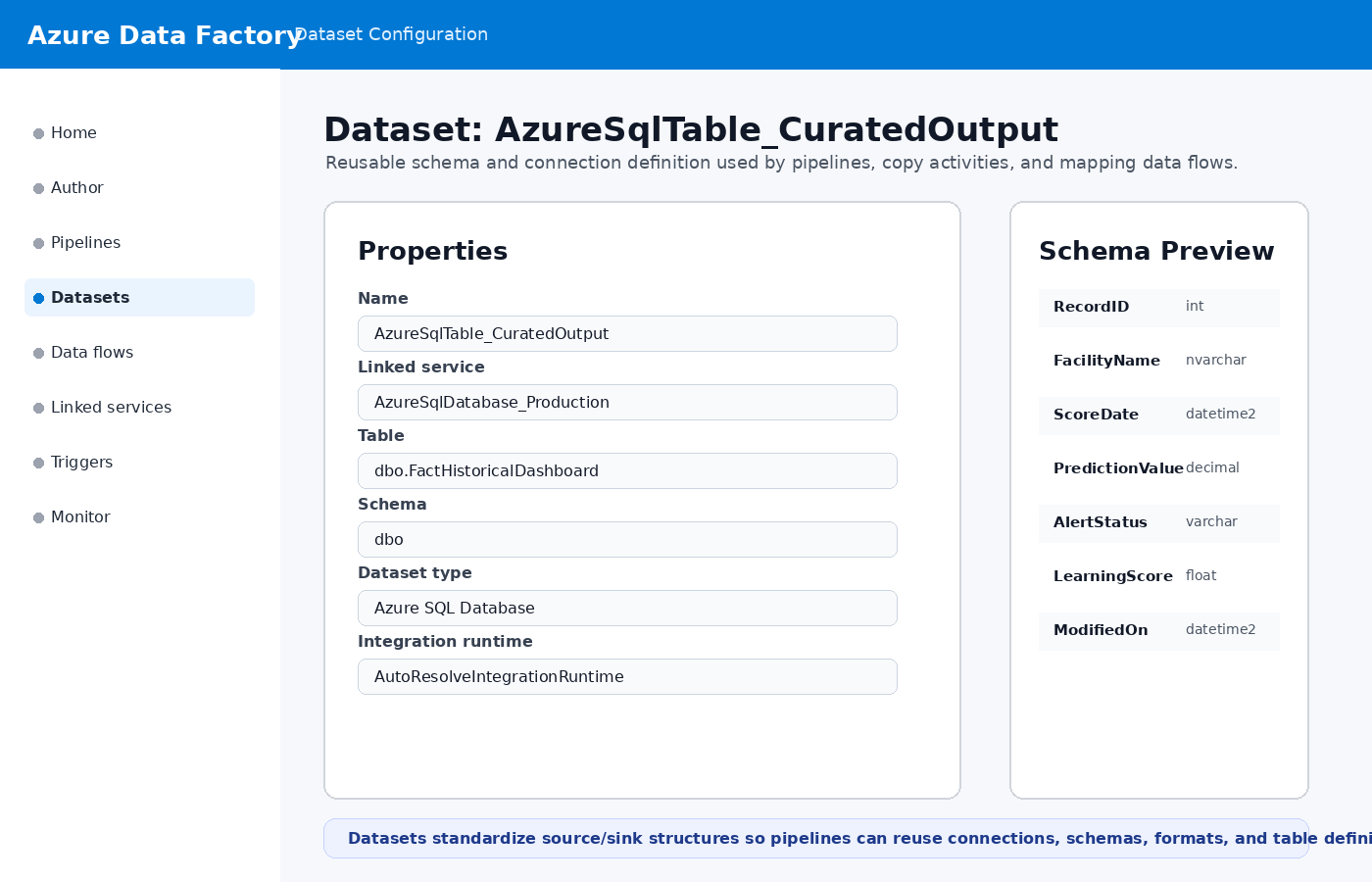
Datasets define reusable structures for files, tables, schemas, formats, and source/sink definitions used by pipelines.
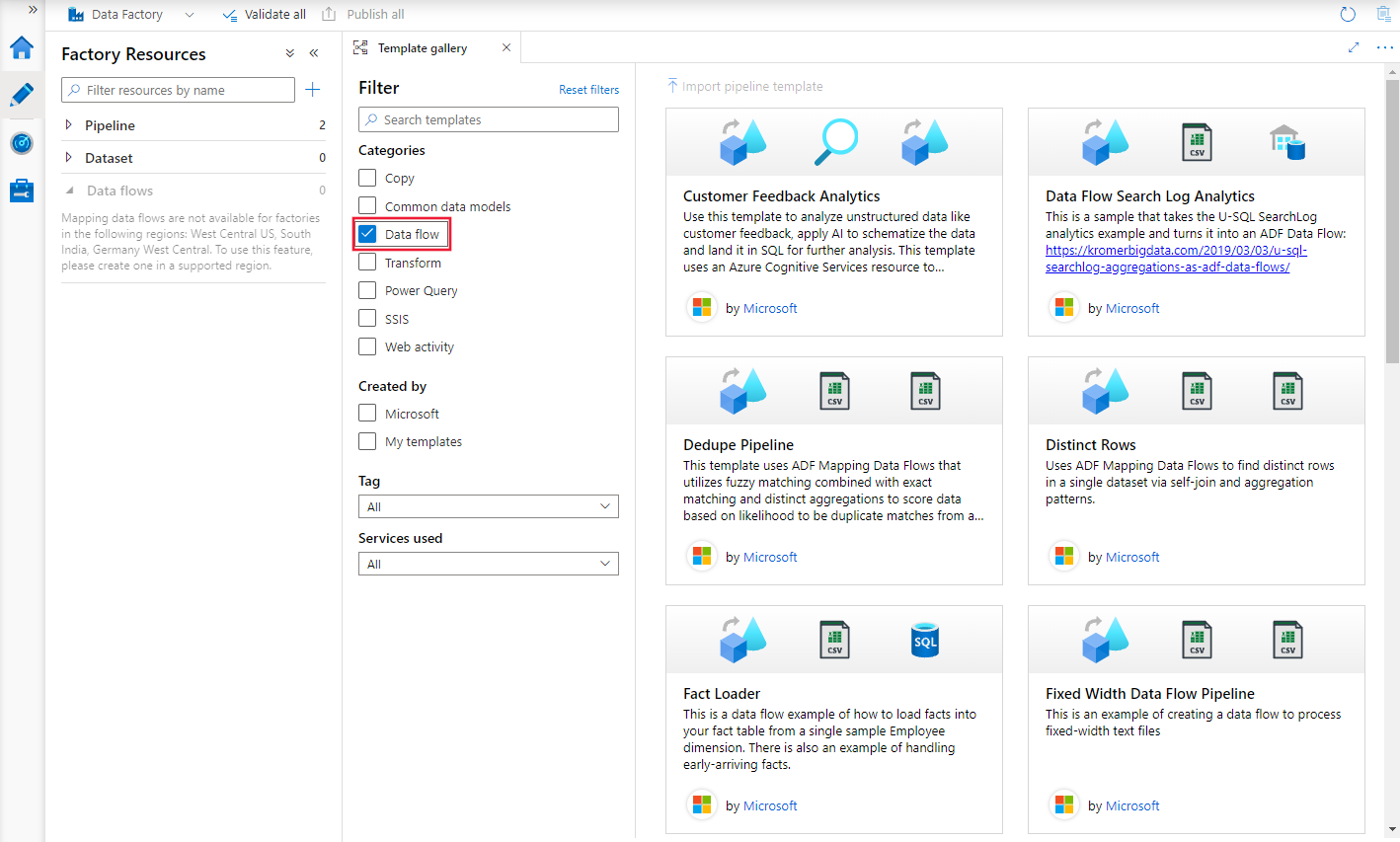
The template gallery provides examples for data flow patterns such as dedupe, fact loading, transformations, and analytics.
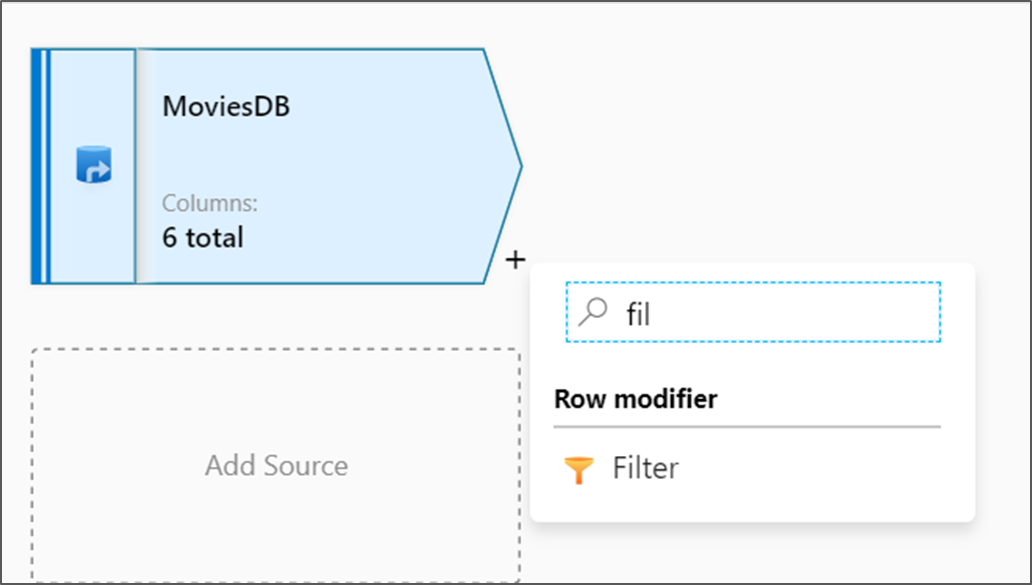
Mapping Data Flows provide Power Query-style visual transformations for filters, joins, aggregates, sources, and sinks.
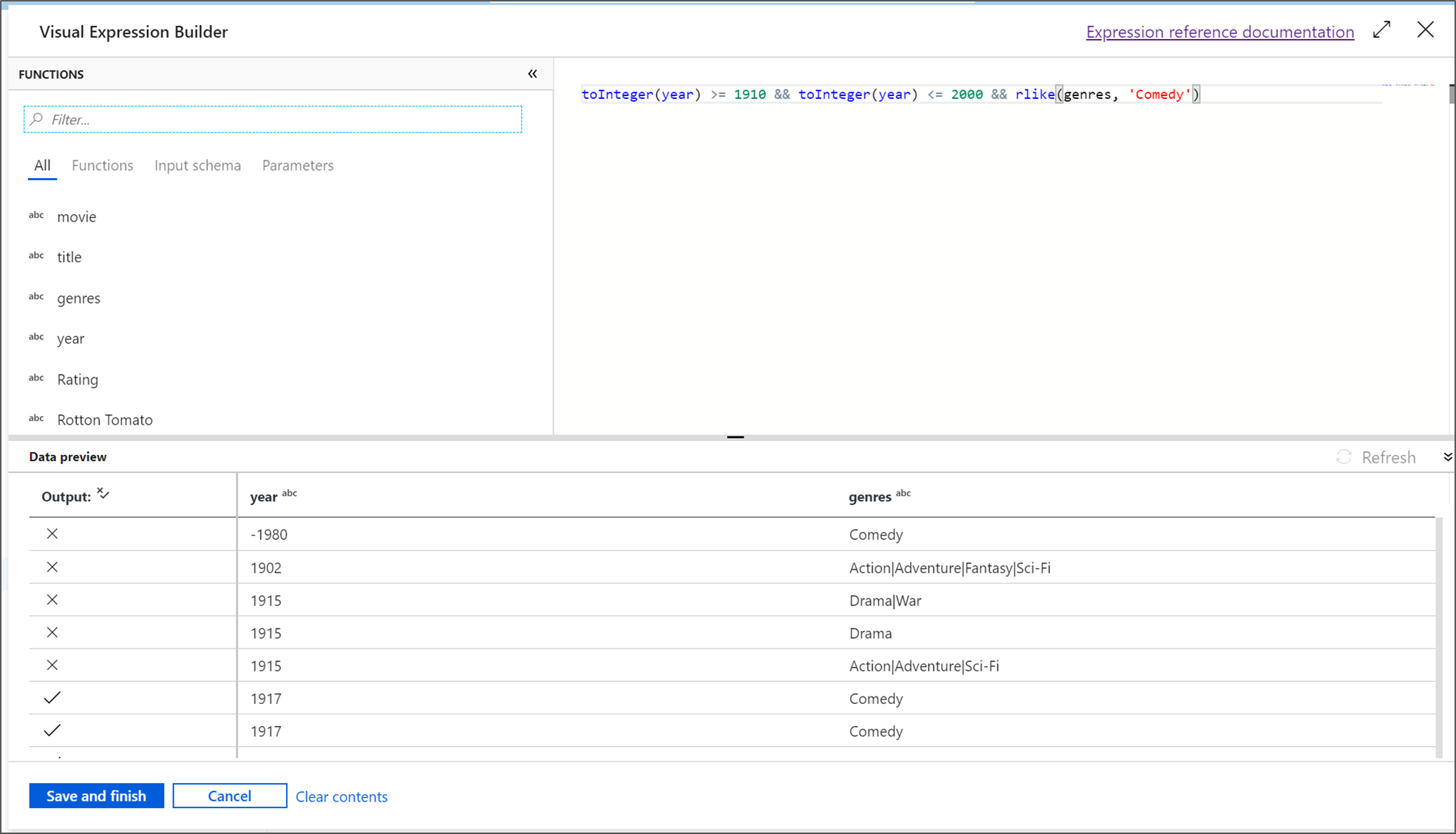
The expression builder supports advanced transformation rules, filtering, derived columns, and data-shaping logic.

Data preview validates transformations before production runs, showing transformed rows, schema changes, and output values.
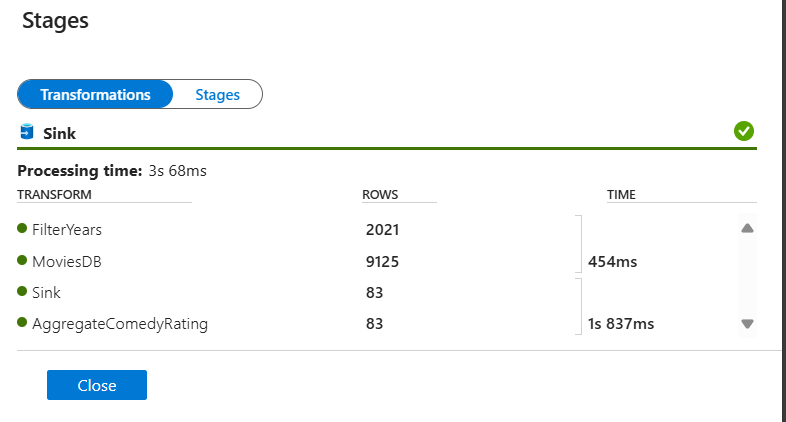
Monitoring shows pipeline success, stage timing, row counts, partition activity, and transformation-level diagnostics.
APIs, SQL, Cosmos, files, RSS, streams, SaaS, and operational systems.
Secure connections, credentials, integration runtimes, and managed identity.
Reusable definitions for files, tables, formats, schemas, and endpoints.
Copy, Data Flow, Lookup, If Condition, ForEach, notebooks, and triggers.
Notebook execution, Delta Lake, ML features, simulations, and analytics.
Azure SQL, lakehouse, Cosmos, Power BI, ML Studio, alerts, and learning.
This pattern lets Data Factory orchestrate the entire integration lifecycle: connect securely to source systems, define reusable datasets, run transformations, execute Databricks when advanced processing is needed, land curated results, and monitor each run for reliability and traceability.