Scalable data engineering, analytics, machine learning, simulation, GPU compute, notebooks, app code, pipelines, jobs, and reporting solutions built with Python in Azure Databricks.
Databricks provides a scalable Python execution layer where notebooks, jobs, pipelines, files, GPU compute, and Delta tables work together. Evolvement LLC uses Databricks to transform raw data into analytics-ready, model-ready, and dashboard-ready outputs.
The screenshots below are Azure/Databricks-style visuals packaged locally with this page so they render reliably. They show GPU compute, Python notebooks, app.py, index.html, parallel jobs, pipelines, and architecture.
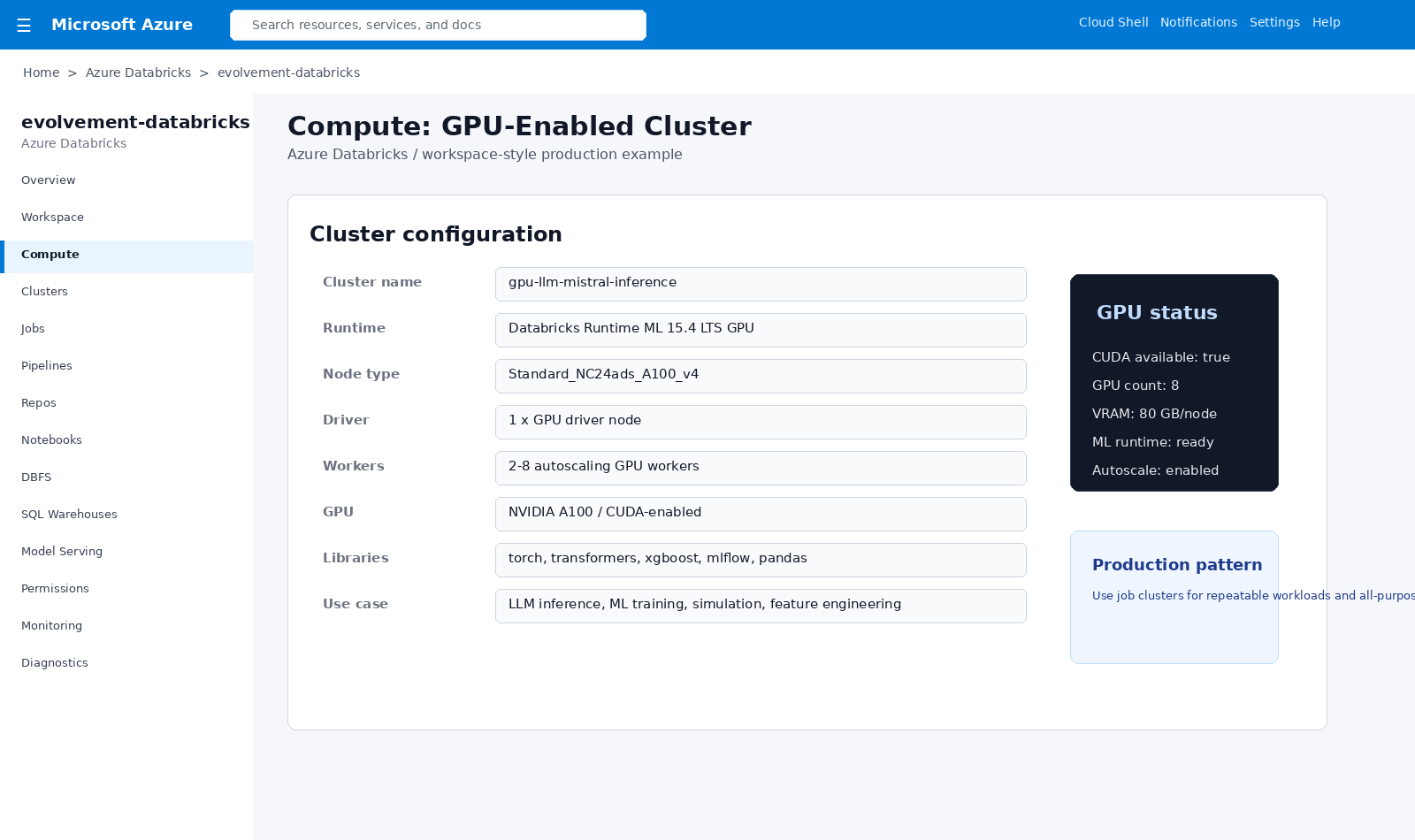
GPU-enabled Databricks compute for LLM inference, ML training, embeddings, simulation, and high-performance analytics.
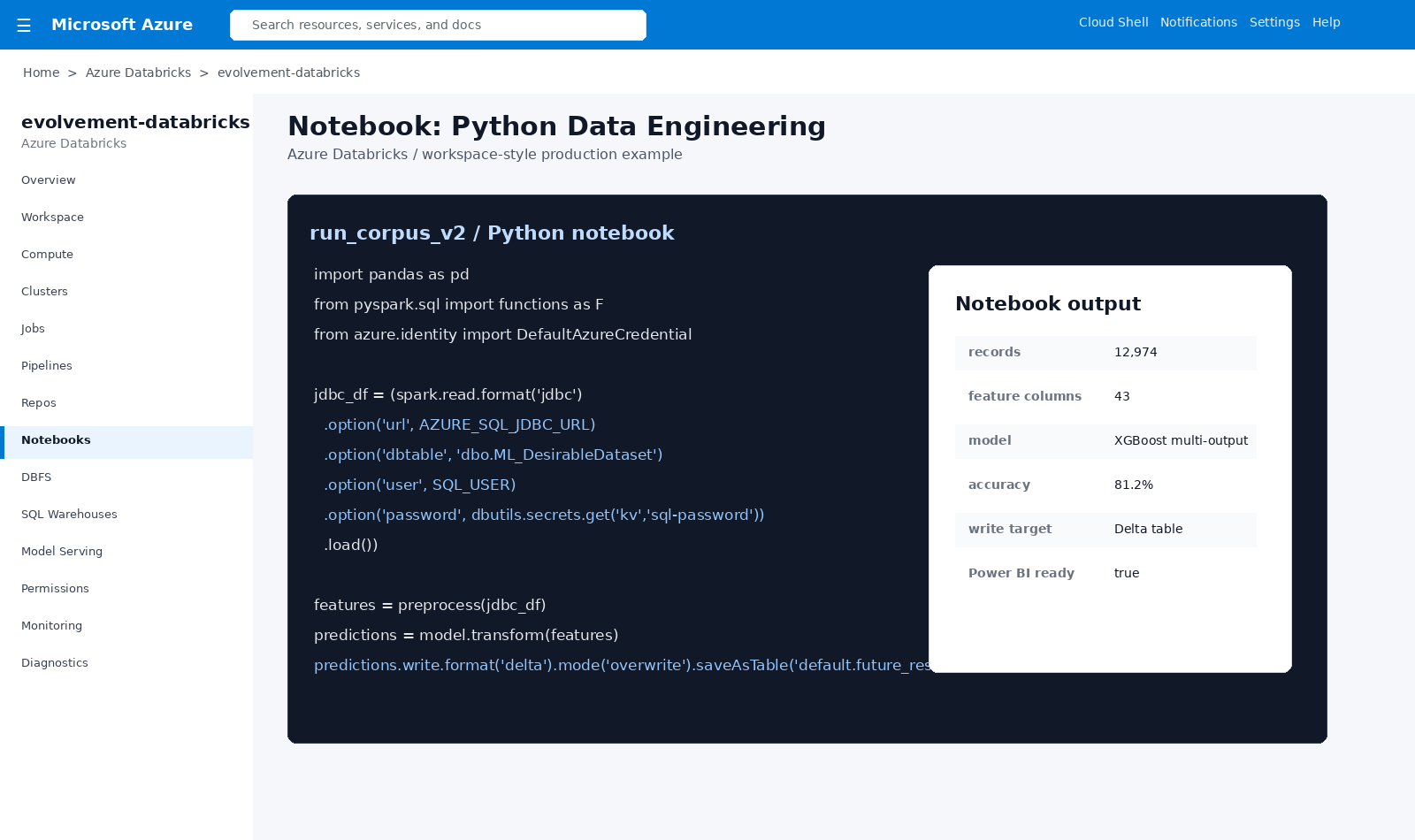
Python notebook connecting to Azure SQL, transforming data, scoring models, and writing curated Delta results.
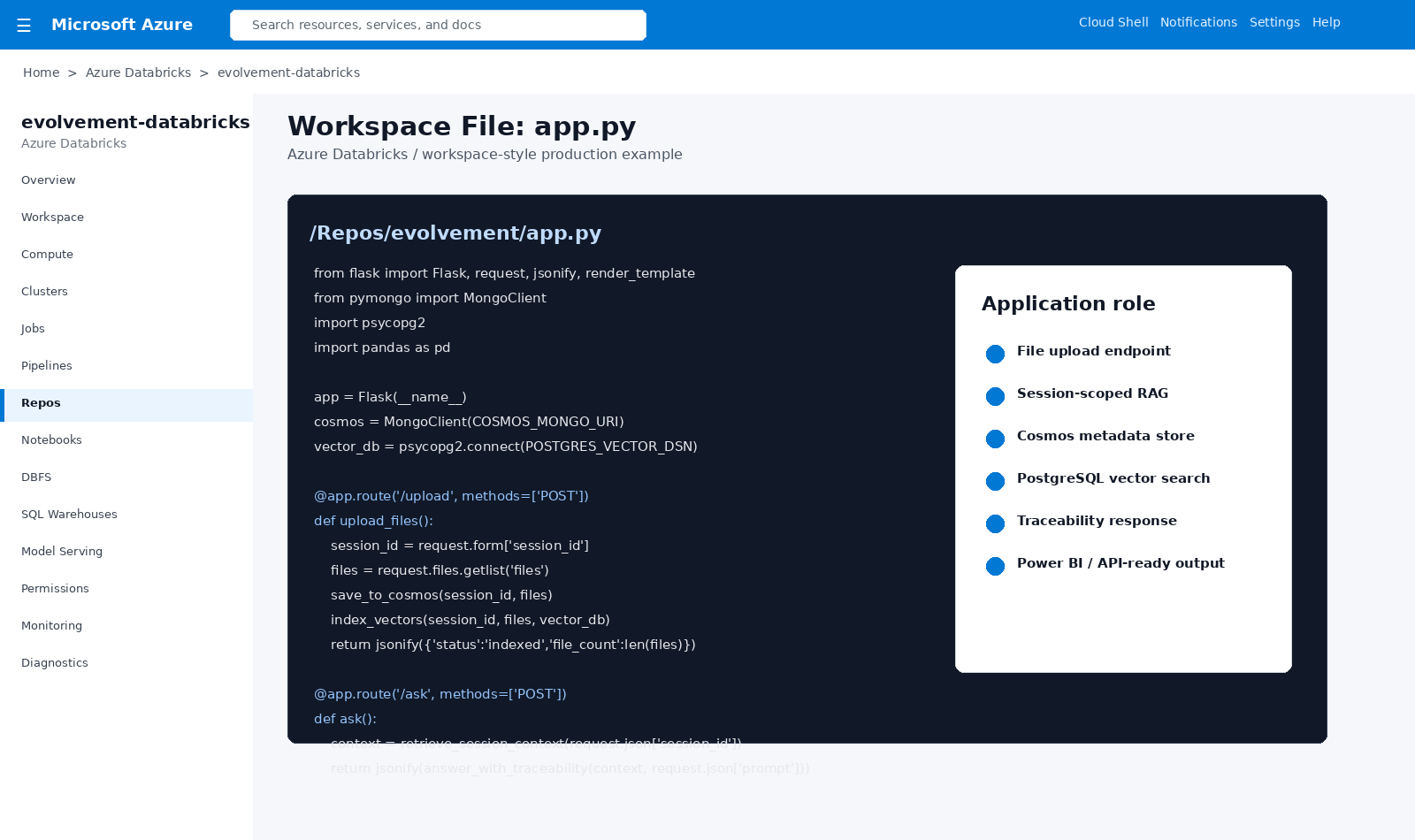
Python web app code for upload, Cosmos storage, PostgreSQL vector search, RAG, and traceability endpoints.
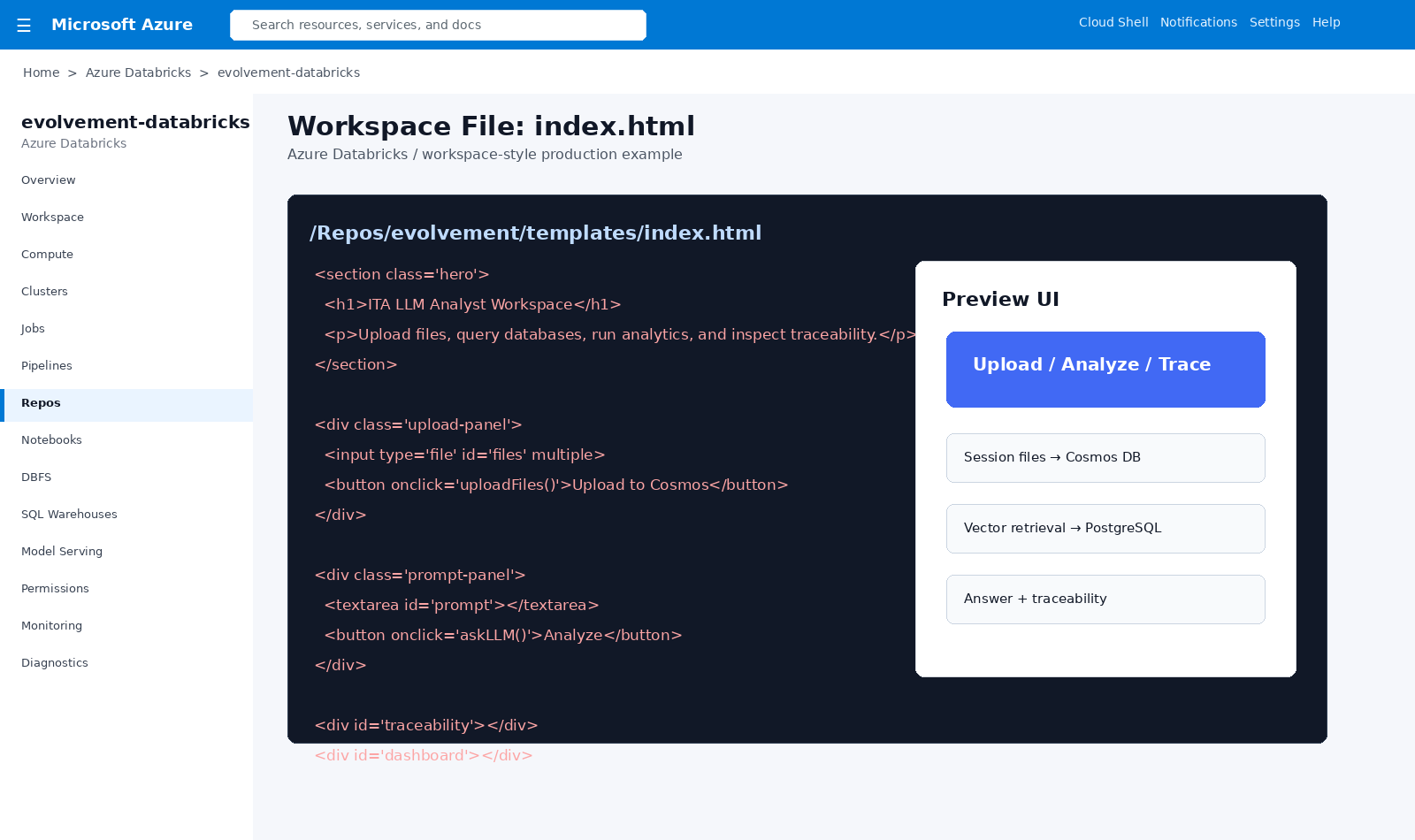
HTML front-end file supporting uploads, prompts, analysis, dashboards, and traceability display.
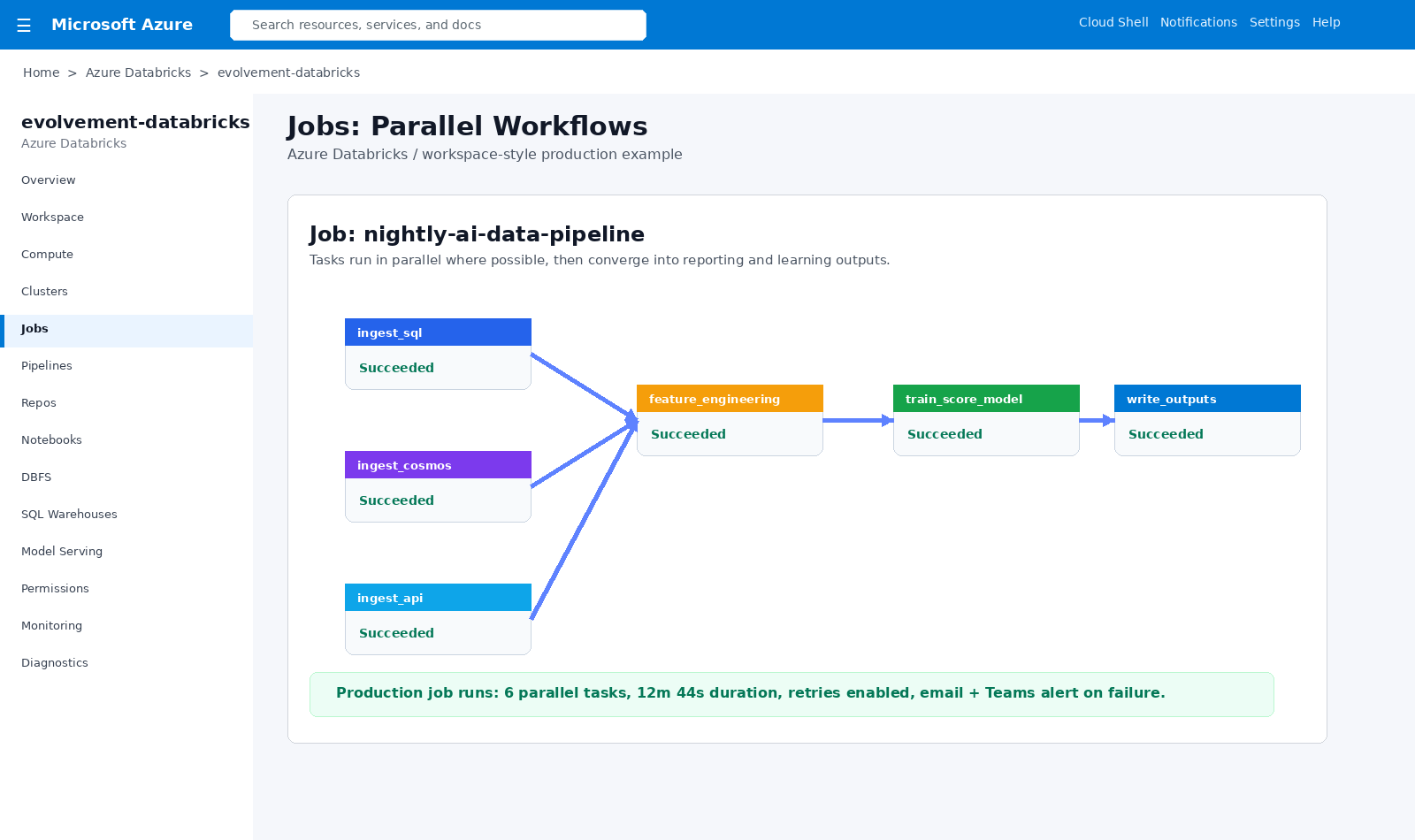
Parallel job graph running SQL, Cosmos, and API ingestion before converging into feature engineering and model scoring.
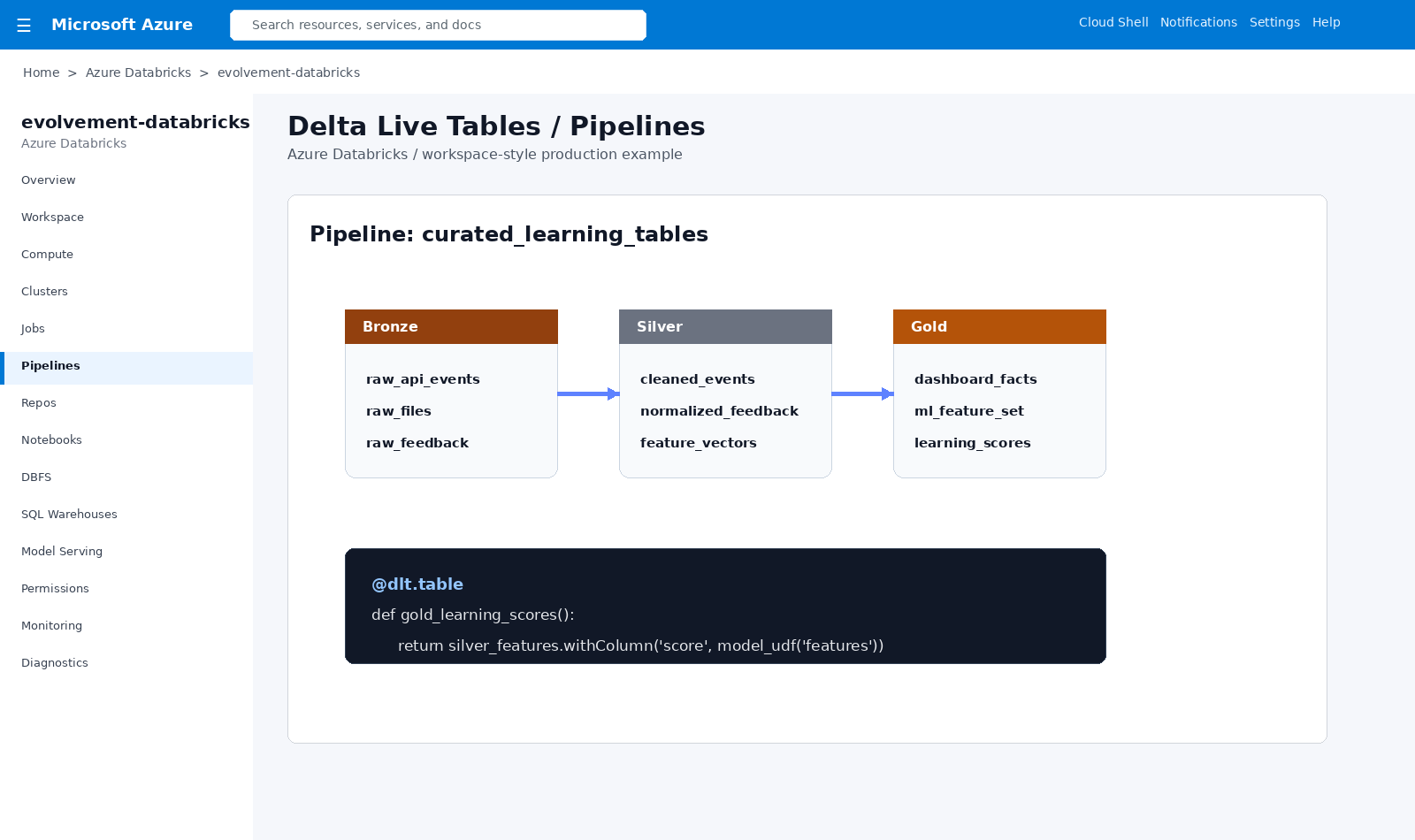
Bronze, silver, and gold pipeline pattern for curated tables, ML features, dashboard facts, and learning scores.
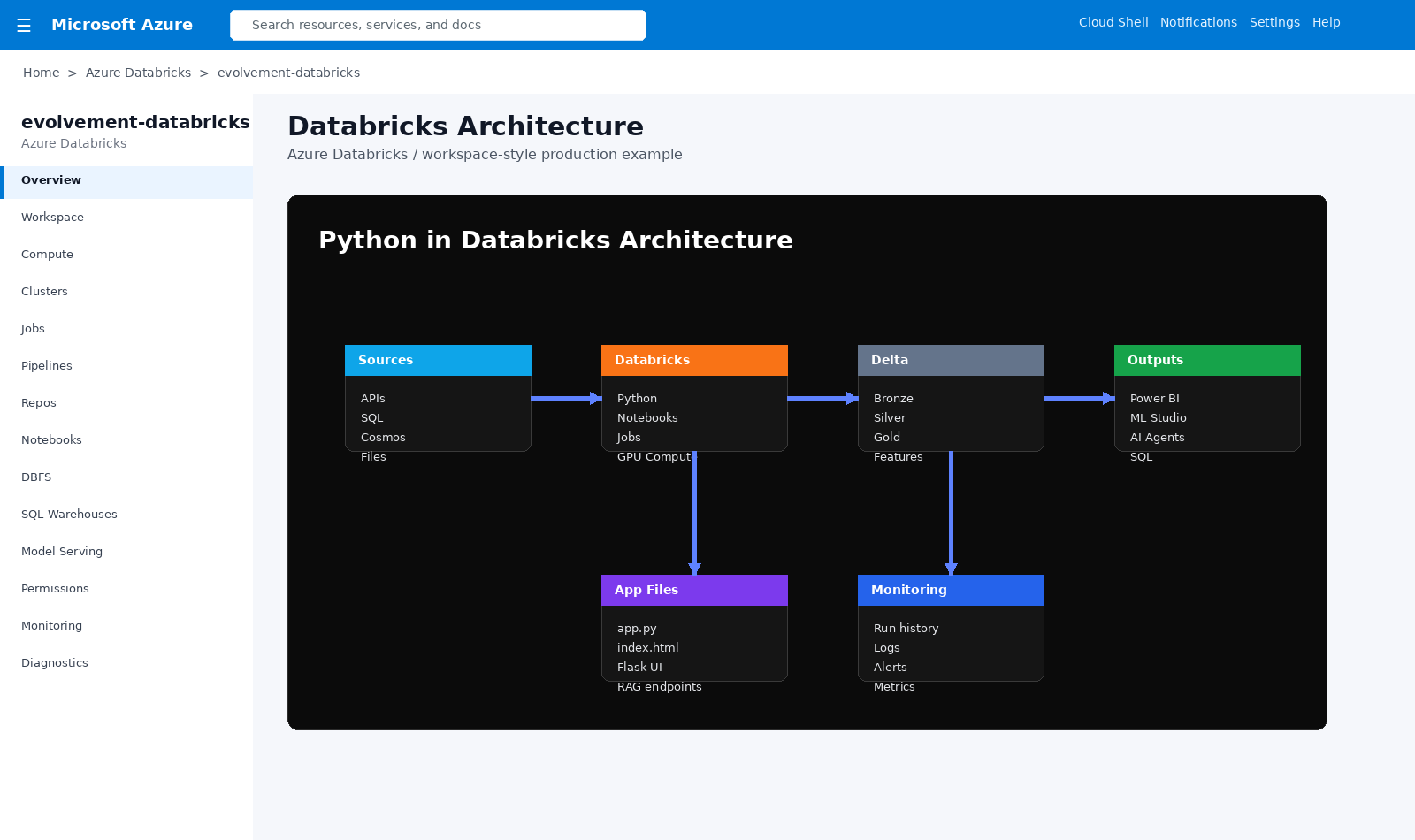
Sources, Databricks, Delta, app files, monitoring, Power BI, ML Studio, and AI agents connected into one data platform.
Azure SQL, APIs, Cosmos, files, streams, and operational systems.
CPU and GPU Databricks clusters for notebooks, jobs, ML, and inference.
Notebooks, app.py, PySpark, pandas, MLflow, XGBoost, transformers, and utilities.
Jobs, workflows, parallel tasks, Delta Live Tables, and bronze/silver/gold layers.
Delta tables, Azure SQL, PostgreSQL vectors, Power BI, ML Studio, and AI agents.
This pattern gives organizations a scalable Python execution environment where Databricks handles data engineering, machine learning, GPU workloads, parallel jobs, web application code, notebooks, and production outputs from one governed workspace.