GPU-backed private LLM solutions using TinyLlama and Mistral 7B for secure document analysis, RAG, AI agents, session-scoped retrieval, Cosmos/Mongo metadata, PostgreSQL vectors, and traceable decision support.
This architecture keeps models, source files, metadata, vectors, and feedback in controlled Azure services. Cosmos DB stores unstructured session records, PostgreSQL stores vector intelligence, GPU compute serves TinyLlama and Mistral, and App Service exposes the secure web experience.
The screenshots below are Azure-style visuals packaged locally with this page so they render reliably. They show GPU compute, model endpoints, Cosmos session storage, PostgreSQL vectors, App Service configuration, RAG architecture, and monitoring.
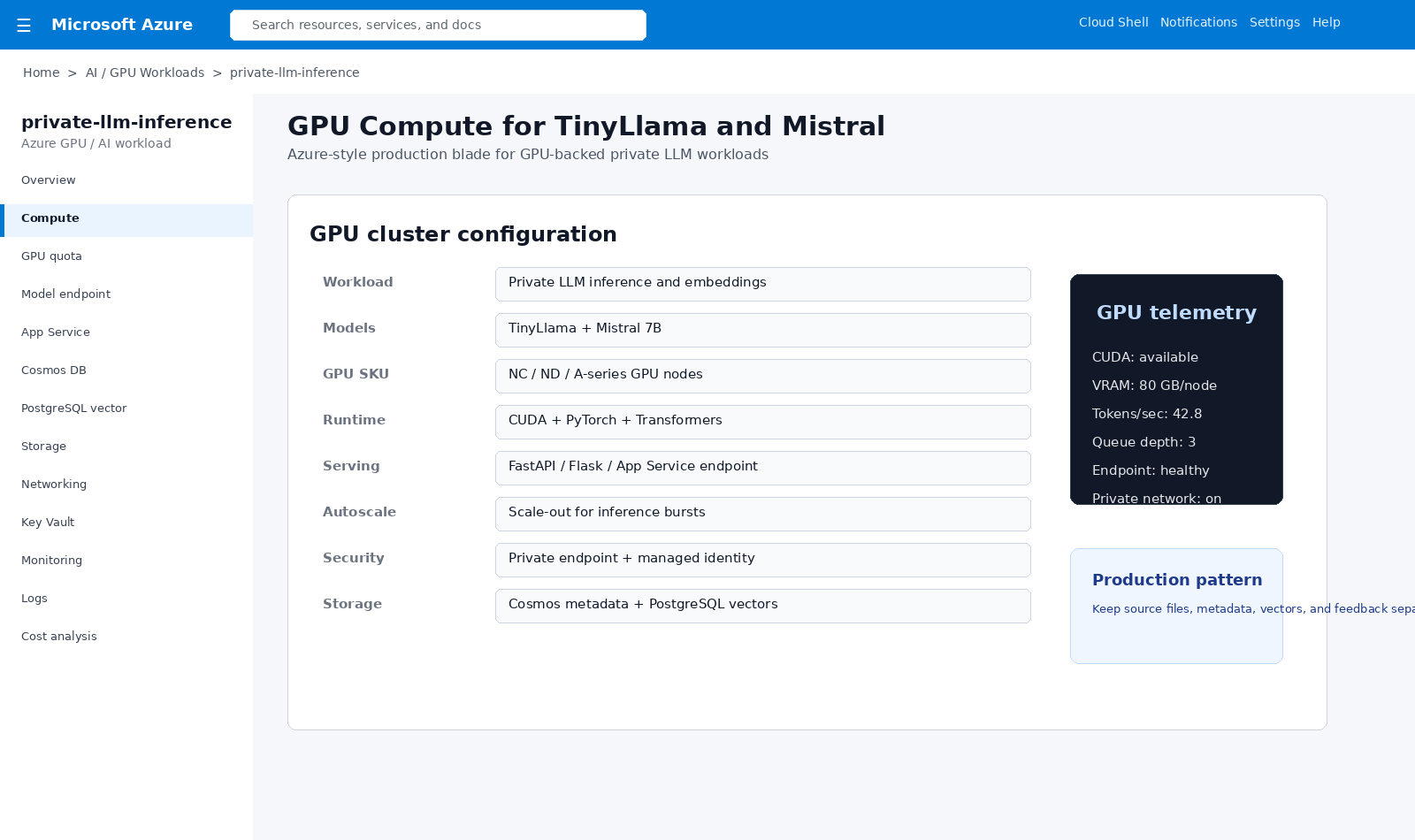
GPU-enabled compute configuration for LLM inference, embeddings, ML training, simulation, and high-performance workloads.
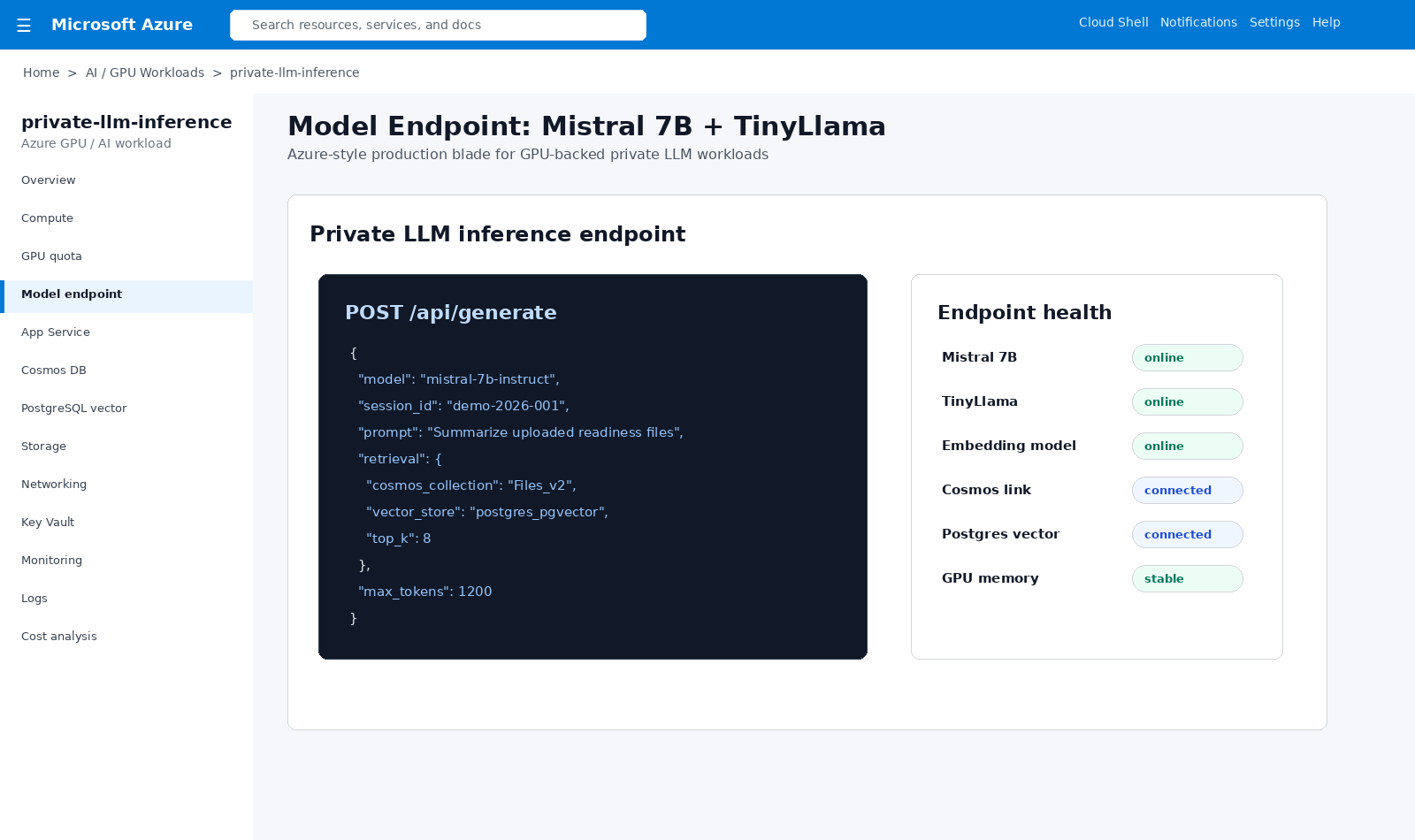
Inference endpoint pattern for Mistral 7B, TinyLlama, embeddings, retrieval, and session-based generation requests.
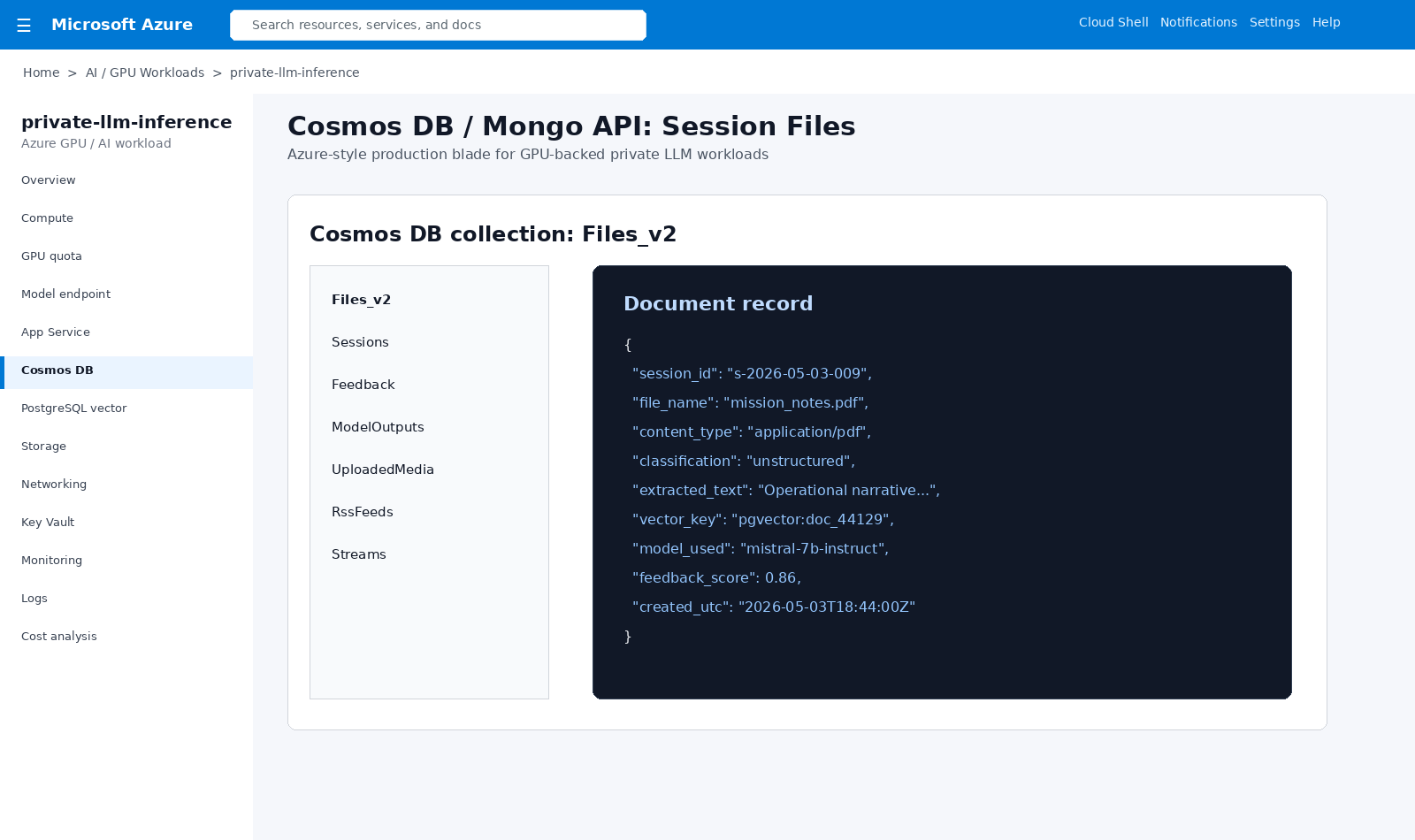
Session-scoped unstructured records, files, extracted text, feedback, model outputs, and JSON metadata.
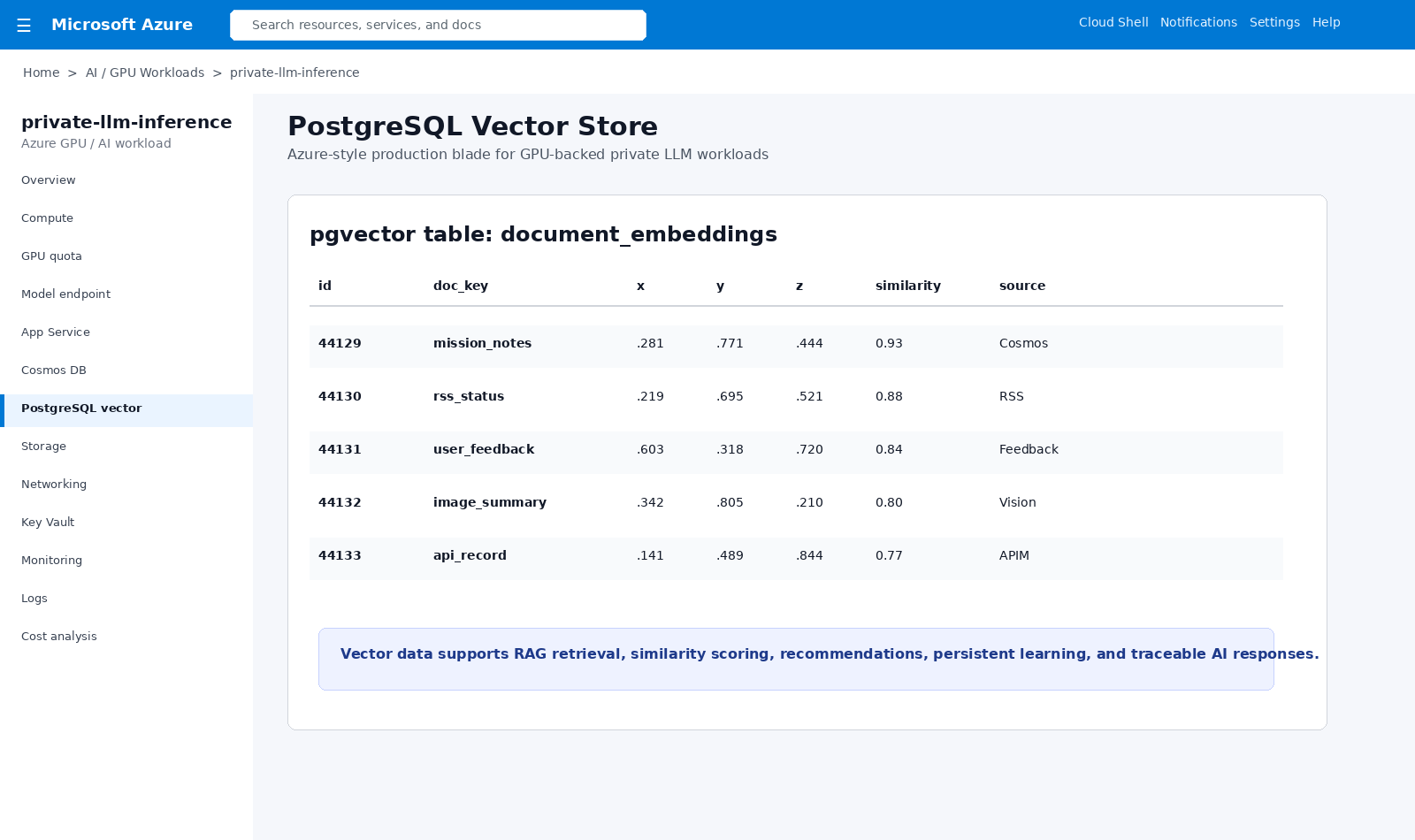
Vector table for embeddings, x/y/z scoring, similarity ranking, recommendations, and traceable RAG retrieval.
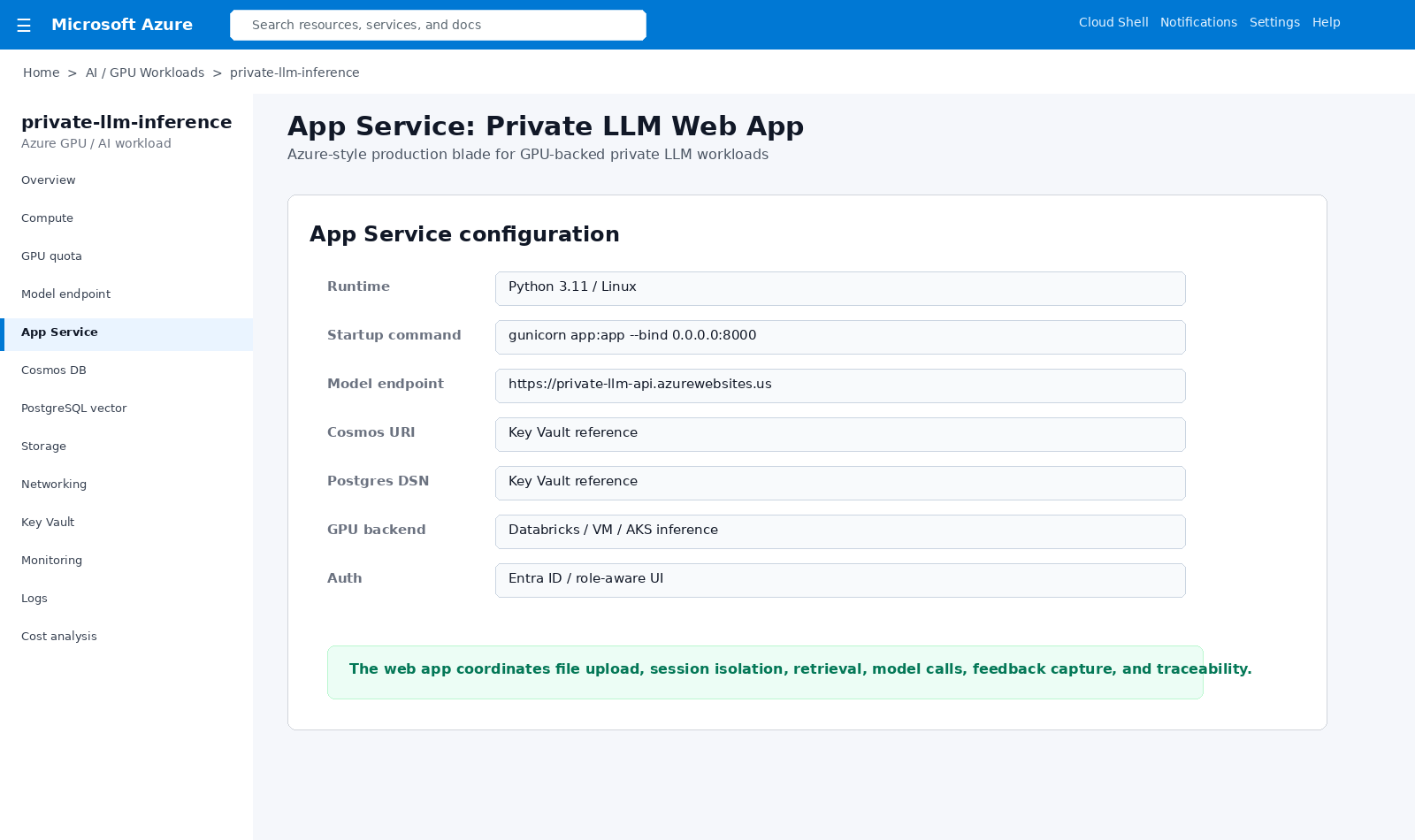
Secure Python web app configuration for uploads, model calls, Cosmos storage, PostgreSQL vectors, and traceability.
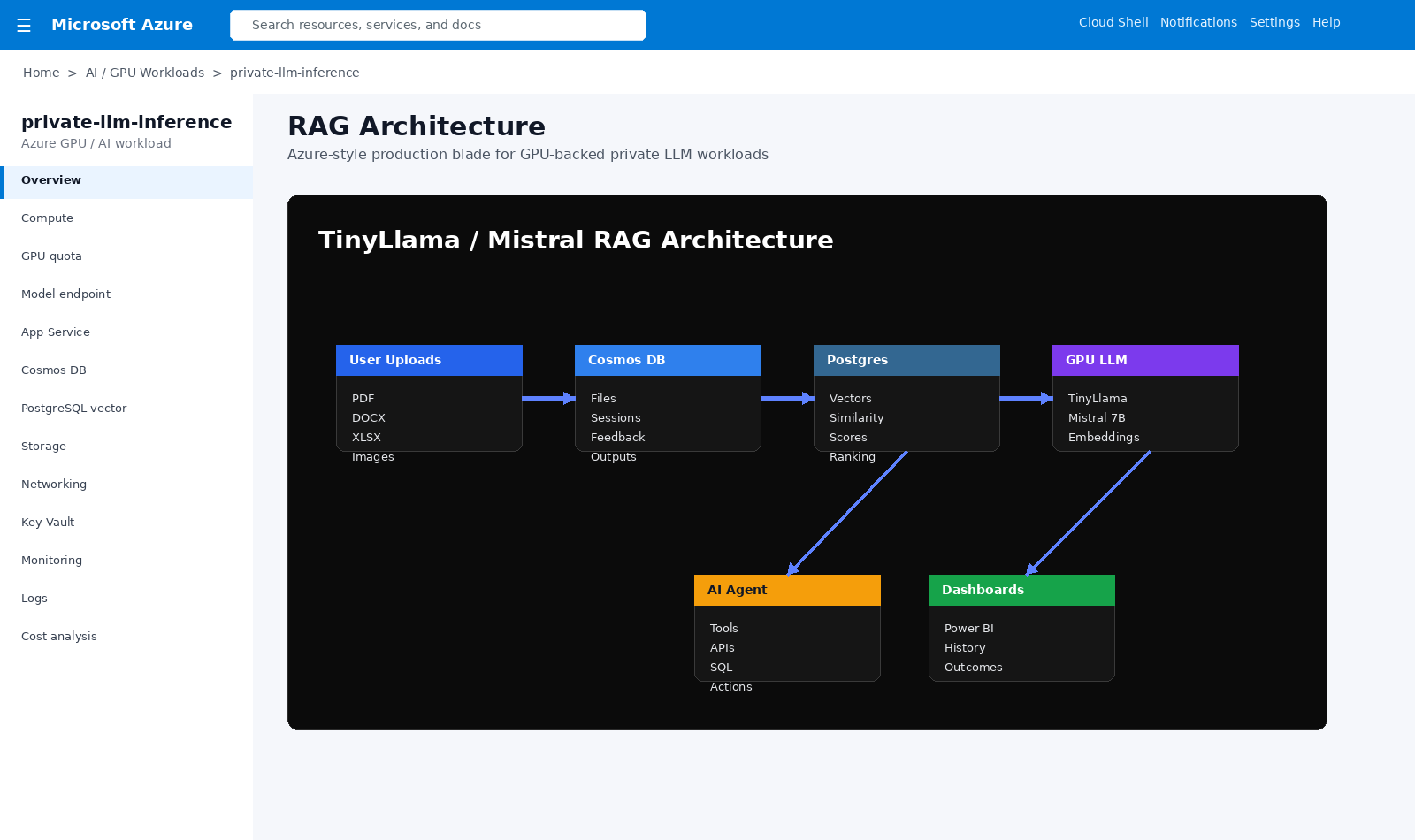
Files, Cosmos, PostgreSQL vectors, GPU models, AI agents, dashboards, and persistent learning working together.
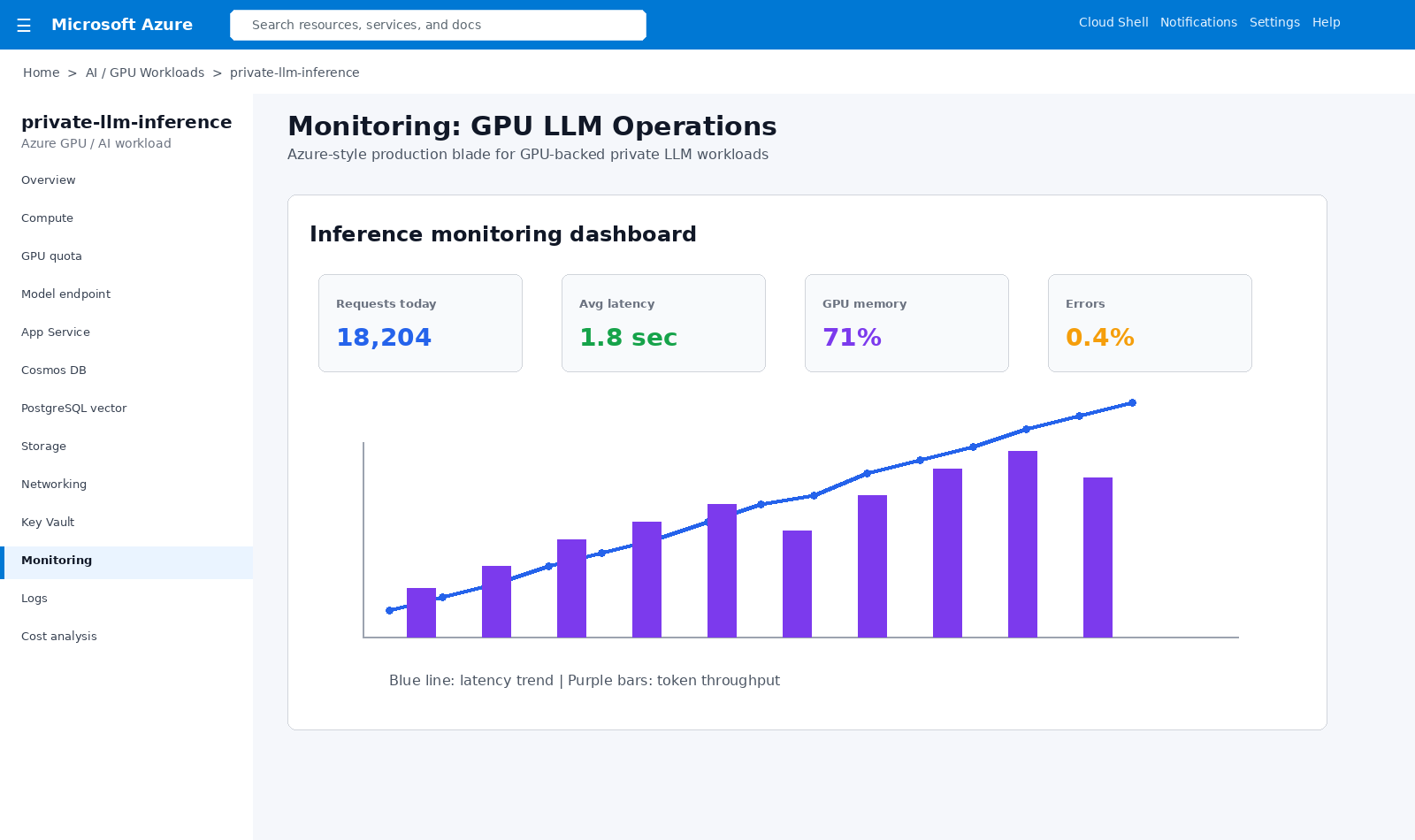
Operational dashboard for requests, latency, GPU memory, token throughput, errors, and model health.
Files, feeds, images, documents, SQL records, user feedback, and operational narratives.
Session metadata, extracted text, unstructured JSON, model outputs, and feedback.
Vectors, x/y/z scoring, similarity, ranking, retrieval, and learning history.
TinyLlama, Mistral 7B, embeddings, inference, summarization, and reasoning.
Answers, citations, dashboards, decisions, alerts, agents, and persistent learning.
This pattern gives organizations a private, traceable AI architecture where each session is isolated, documents are stored as unstructured records, vectors power retrieval, GPUs accelerate model inference, and feedback improves recommendations and outcomes over time.